Contents
论文发表在AAAI 2020阅读笔记,暂时没有官方的代码。
论文主要提出了SPT(Sampling Perturbation Technology)和WPT(Weighted Perturbation Technology)两种方法,使得生成的音频对抗样本更低噪声、鲁棒、快速生成(分钟级)。
没有复现和实验(没找到作者的代码),属于纸上谈兵。
Introduction
生成音频对抗样本的三大困难:
- 计算资源多、计算时间长,花费时间以小时计;
- 录音再重放会引入噪声,现有方法生成的对抗样本鲁棒性不强;
- 适合作为音频对抗样本loss函数的度量方法,缺乏研究(图像一般用lp范数)
作者的工作:
- 使用SPT和WPT两种方法,控制扰动的样本点数量和更新权重,以提高鲁棒性和生成效率;
- 研究了loss函数使用不同度量方法的效果;
- 生成对抗样本只需4-5min(相较于以前的>1h);
CTC介绍:https://distill.pub/2017/ctc/
样本:https://sites.google.com/view/audio-adversarial-examples/
代码:无
Related Work
两种类型的攻击:
- speech-to-label:分类问题
- speech-to-text:语言转文字
论文讨论第二种,更具现实意义。
- Carlini and Wagner 2018实现让ASR将一段话语识别为另一目标文字
- CommanderSong实现在音乐中嵌入扰动,让ASR识别为目标文字,且是物理攻击
待优化方向:低噪声、鲁棒性、生成速度
Background
威胁模型,攻击的目标ASR满足的条件:
- 核心构件是RNN
- 易被对抗样本攻击,攻击的结果作为下面测试的baseline
- 开源,以作白盒攻击
文章中的攻击:
- 威胁模型是:Deepspeech
- 只测试了白盒攻击
设
其中,
- SNR(Signal-to-Noise Ratio),即
- WER(Word Error Rate),即
- Success Rate,即
,其中 是攻击成功的样本 - Robustness Rate,即
,其中 指添加噪声的映射,即添加噪声后的success rate
Methodology
Sampling perturbation technology
这里,以CTC loss为例:
是输入的语音(向量), 是 的语义信息(即phrase), 是概率分布(采用CTC的ASR的输出结果) 和 表示 的第 帧(向量值)及其概率分布(字符概率分布) 表示去除重复字符和空字符之前的tokens,有一个 ,有其对应的text输出结果 , 的长度和 相同 - 有一个概率分布
,对应于不同的 ,有这个 的概率值,这个值就是 ,即每帧 对应的概率相乘 - 有一个概率分布
,再有一个phrase记为 ,则有一组 - 对于一个概率分布
,语义信息为 的概率为所有对应的tokens概率相加,即
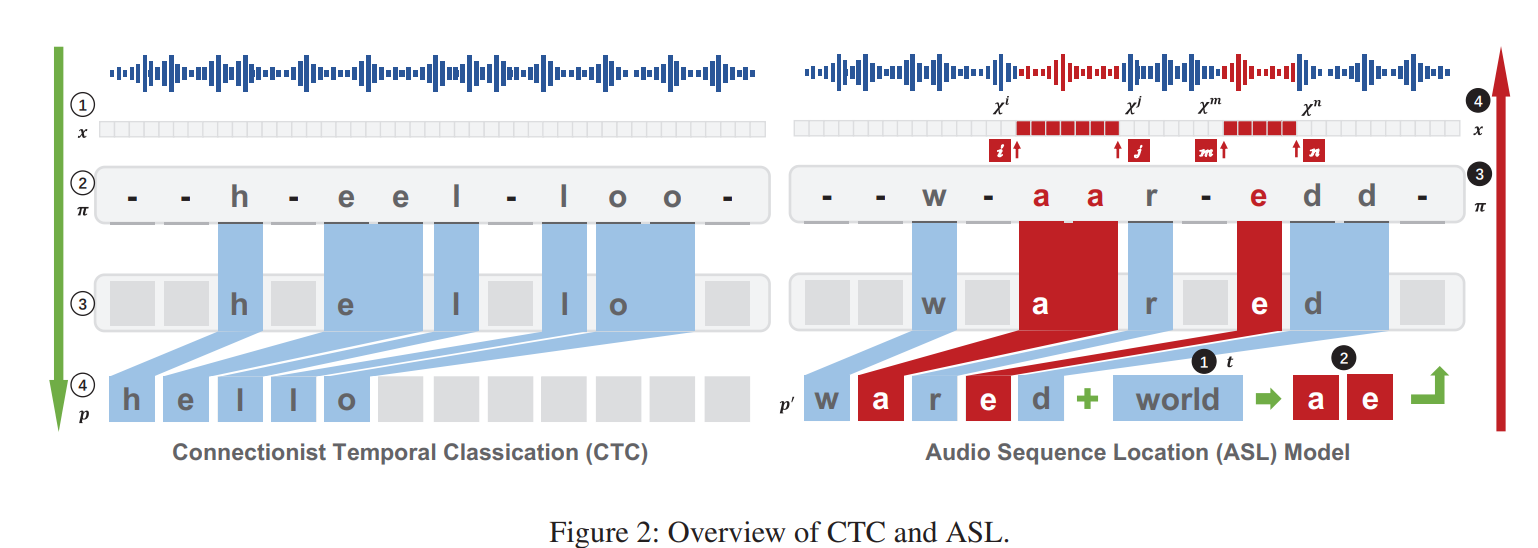
以前的工作是通过扰动
设被扰动后的tokens为
(看起来是把
Weighted perturbation technology
实验发现,在将语音原来的phrase调整到目标phrase的时候,超过一半的时候花在了两者Levenshtein距离在3-0的时候。
使用ASL(Audio Sequence Location)模型去寻找目前结果的phrase和target phrase之间的区别,给出tokens中
同时在levenshtein距离从1到0的时候,降低learning rate。